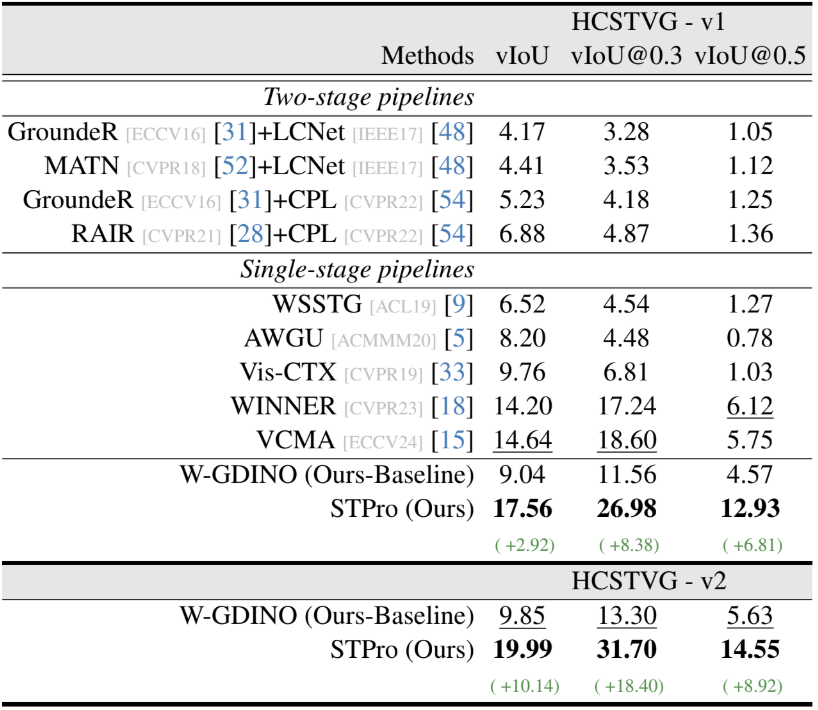
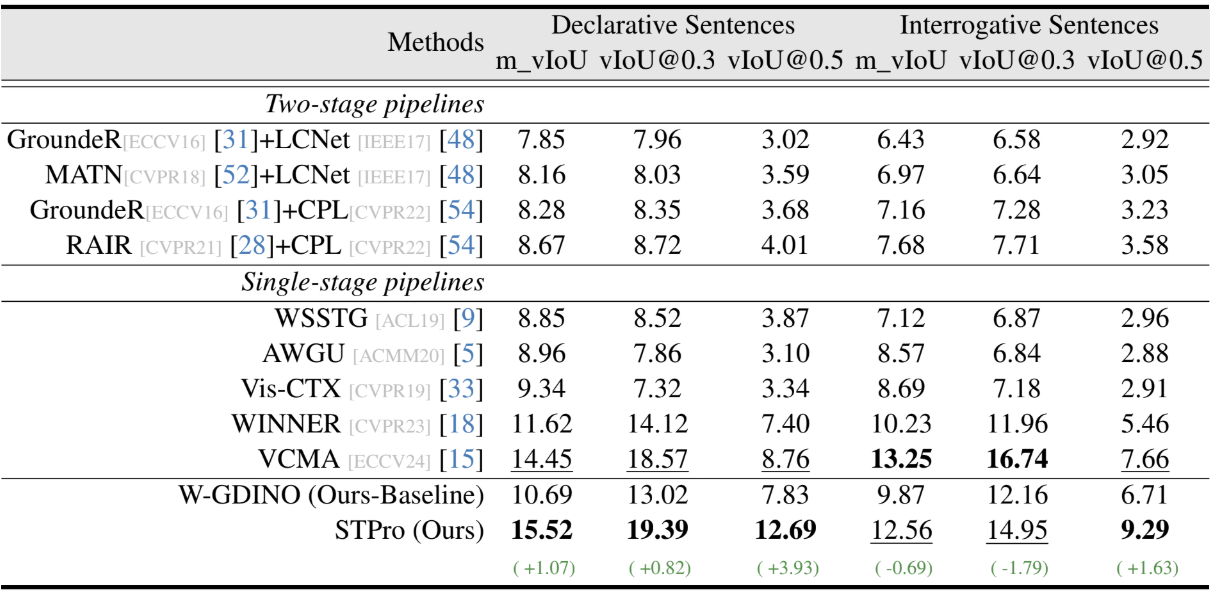
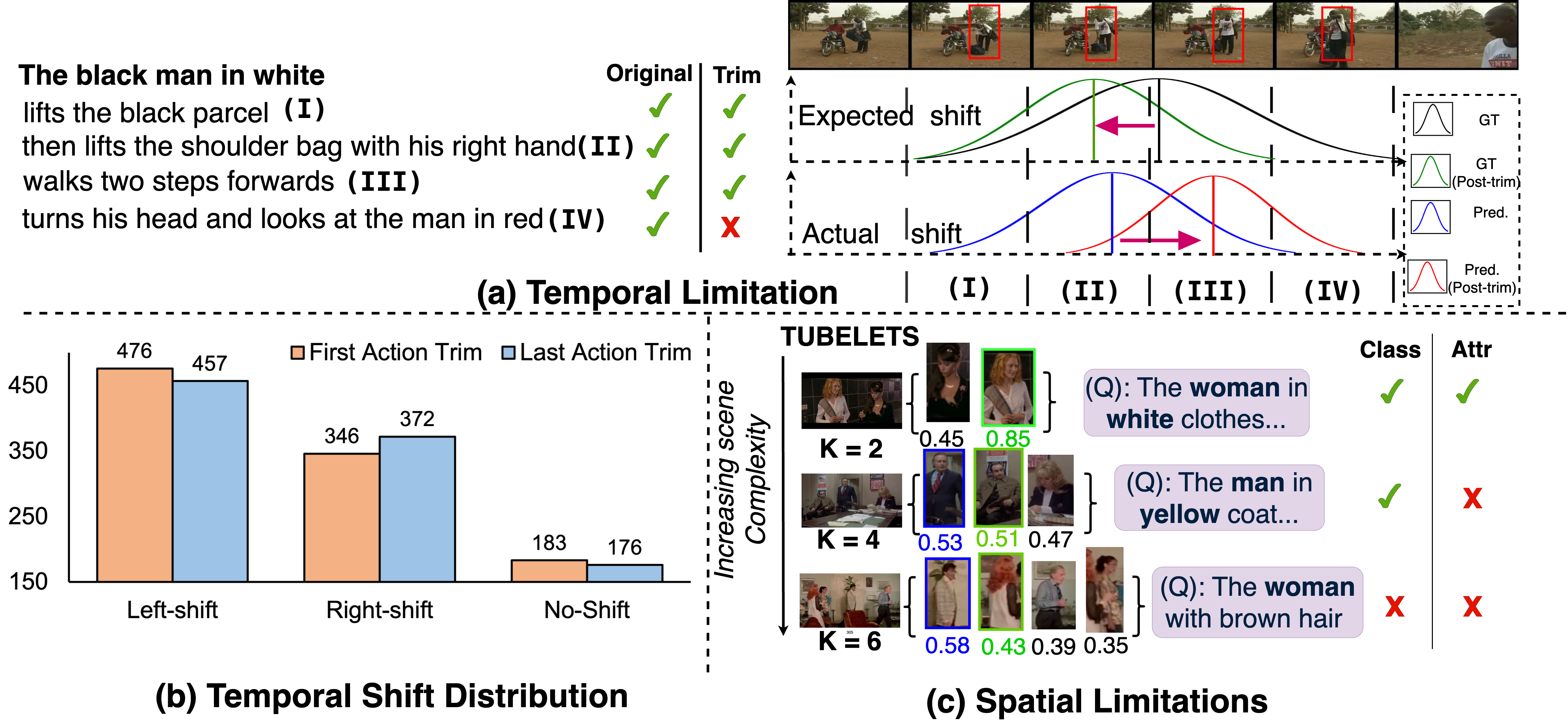
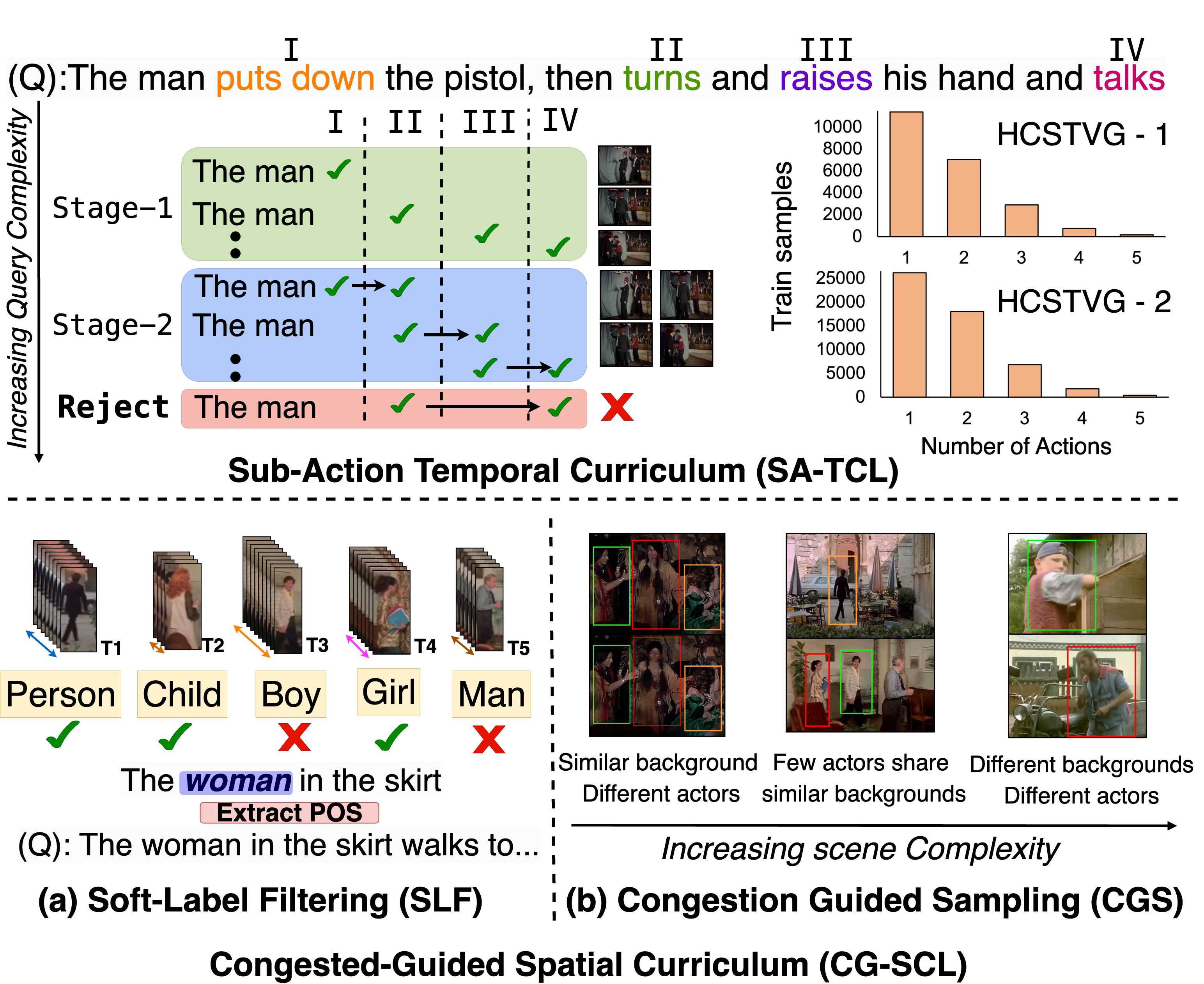
In this work, we study Weakly Supervised Spatio-Temporal Video Grounding (WSTVG), a challenging task of localizing subjects spatio-temporally in videos using only textual queries and no bounding box supervision. Inspired by recent advances in vision-language foundation models, we investigate their utility for WSTVG, leveraging their zero-shot grounding capabilities. However, we find that a simple adaptation lacks essential spatio-temporal grounding abilities. To bridge this gap, we introduce Tubelet Referral Grounding (TRG), which connects textual queries to tubelets to enable spatio-temporal predictions. Despite its promise, TRG struggles with compositional action understanding and dense scene scenarios. To address these limitations, we propose STPro, a novel progressive learning framework with two key modules: (1) Sub-Action Temporal Curriculum Learning (SA-TCL), which incrementally builds compositional action understanding, and (2) Congestion-Guided Spatial Curriculum Learning (CG-SCL), which adapts the model to complex scenes by spatially increasing task difficulty. STPro achieves state-of-the-art results on three benchmark datasets, with improvements of 1.0% on VidSTG-Declarative and 3.0% on HCSTVG-v1.