 Blogs/ Articles / News
Blogs/ Articles / News
AWS - Acquired Podcast (Partial)
- Gross income from AWS > Gross income from retail
- There exist several stories about the origins of AWS -
- Story #1: Amazon had excess server capacity in Q1-3 so they decided to rent out servers to other businesses in the “off season”. This story is very plausible but most likely false - What would you tell companies in Q4? DEC servers cost them 80% margins, didn’t make sense to have extra capacity in anyway.
- Story #2: AWS was pitched by Tim O’Riley to Bezos. The idea was that you could do business with thousands of other companies without needing formal contracts secured through a BD team. The first API that Amazon made available was offering their product catalogue, which covered basically everything. They shared revenues.
- Amazon was one of the first companies to start code freezes in November.
Interesting prompt ideas L1 & L2
- Demarkation tags to separate out parts of input: <example></example>
- Textual FSM: Step 1, Step 2. If Step-2 fails then Step-4 else Step-3. I found that this works in practice for simple instructions. For simple instructions, operation order can be specified causally as a paragraph too.
- Evaluating improvements: Often we’d tweak a prompt, it works better on the samples where it was failing but starts to perform worse on samples it was already doing well at. Here, is a good reference of what performance delta to aim for to confirm that your new prompt actually offers some improvements based on sample size
- Automode: Ask the “Agent” to make a plan for itself and subsequently use tools to achieve those steps. Reflection (did I sufficiently achieve what I was trying to achieve with this tool use / step?) is very helpful in long tool-use chains.
- Identity prompts: System prompts are taken lightly by most prompters. It is very very difficult to achieve the same outcome of a system prompt by direct prompting.

Target performance delta for verified improvements with a new prompt
- What I’ve found from experience:
- For FSM like operations, in-context examples help significantly, almost like a reasoning example.
- For strict, fixed format JSON outputs which contain anyOf for optional parameters : explaining construction within the JSONSchema definition using descriptions helps the model logically construct the correct required JSON more than specifying it directly in the model prompt.
 Books
Books
Blockchain Governance - MIT Press Essential Knowledge Series(Contd)
-
Ethereum popularized the concept of smart contracts, allowing for the creation of DApps. A smart contract is deterministic code that runs on the blockchain. When interacted with, it ALWAYS executes. Solidity is a Turing complete language, but Ethereum’s gas limits prevent indefinite execution (ex : infinite loops).
-
Tokens & Different kinds of tokens:
- Some are application-specific—you can interact with or use an application only if you hold its associated tokens.
- Some tokens resemble traditional securities like shares—they represent part ownership in on-blockchain projects.
- Governance tokens:
- Allow you to vote on how something is managed, e.g., how the blockchain itself operates.
- The issue with these tokens is that they are inherently plutocratic (favoring wealthier holders).
- Quadratic voting is one proposed solution to reduce plutocracy by weighting votes based on a quadratic cost function, giving minority voices more power.
- Meritocratic tokens were introduced as another countermeasure—these are non-transferable and granted only if specific conditions are met, ensuring voting rights based on merit rather than wealth.
- Non-transferable tokens: Once owned, they cannot be transferred to other members on the blockchain. A real-world example is Soulbound Tokens (SBTs), which could be used in the future for identity verification, reputation systems, or even citizenship.
- NFTs (Non-Fungible Tokens) are popular because they provide guaranteed, verifiable ownership on the blockchain that CANNOT be disputed.
- Authentication tokens: For example, the Bored Ape Yacht Club (BAYC) NFT is highly valued because it grants exclusive access to a private community (~10K holders), events, and other perks. However, its popularity is also driven by brand value and status signaling. Scarcity drives value.
- Some real-world examples of DAOs (Decentralized Autonomous Organizations) that operate using tokens:
- Moloch DAO – investment group for fund allocation.
- Decentraland DAO – governs the metaverse.
- Mirror DAO – decentralized blog content curation.
 Papers
Papers
Compositional Evaluation Benchmark for Fairness in LLMs
- Bias evaluation benchmarks are limited: they generally evaluate one kind of bias in limited social groups in one way. Metrics for different datasets differe slightly making an apples to apples comparison difficult. There is no easy way to figure out what bias your model has and then work towards mitigating that bias.
- All (almost) bias datasets can be grouped under :
- Bias type: stereotype or toxicity. Most datasets evaluate steretypes and not toxicity.
- Social group: gender, age, race, religion
- Task (eval method):
- Direct - explicitly ask the model if it detects bias in a sentence or two pick the more biased of two sentences etc.
- Indirect - make the model perform some task, and out of its completions verify whether the model has some inherent bias.
- Using GPT-4 use some existing datasets which don’t have explicit annotations in the formats required, and generate those formats so that you cover a larger variety of combinations of the above 3 classes within the taxonomy. Evaluate models on these datasets / tasks.
- Results:
- GPT-4: Least biased in general; one of the most powerful LLMs today and also used for dataset creation.
- Llama3-8b: Particularly good at recognizing race and age toxicity
- Mistal-7b: Particularly good at recognizing religious toxicity
- Llama-2b: generally most biased
. Direct evaluation uses recognition (yes/no) and selection(more steretypical or toxic of two).")
Direct evaluation of model bias on CEB (crafted dataset). Direct evaluation uses recognition (yes/no) and selection(more steretypical or toxic of two).
The foundations of LLMs (Continued)
-
What kinds of architectural variations exist :
-
Pre vs Post-Norm: Determines whether Layer Normalization is applied before or after the residual connection within a transformer block. Most models, such as LLaMA and GPT-4, use pre-norm, as it improves training stability, especially for deeper networks. Post-norm (as seen in early transformer models) can suffer from unstable gradients.
-
Layer-Norm Type:
- Standard LayerNorm (used in GPT-4, LLaMA): Computes mean and variance over all hidden dimensions and normalizes accordingly.
- RMSNorm (used in LLaMA-2, GPT-J): A variant that only normalizes based on the root mean square of activations rather than full mean-variance normalization, reducing computational overhead.
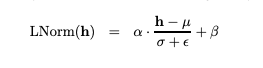
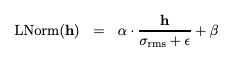
-
-
Number of layers, token dimensionality, number of attention heads:
- LLaMA 7B: 32 layers, 4096 token dimensionality, 32 attention heads.
- GPT-4: (Exact details unknown, but expected to have ~96 layers and >10K token dimensions in larger variants).
-
FFN Activation Function: Determines non-linearity within the feedforward networks inside transformer layers.
- ReLU (Rectified Linear Unit): Used in early transformers but largely replaced due to gradient inefficiencies.
- GeLU (Gaussian Error Linear Unit) (used in GPT-3, GPT-4, LLaMA): Smoother activation than ReLU, enabling better gradient flow.
- GLU Variants:
- SwiGLU (used in PaLM-2, GPT-4, LLaMA-2): Uses a gating mechanism with Swish activation to improve expressiveness.
- GeGLU: Similar to SwiGLU but with GeLU instead of Swish.
- Removing Bias from Affine Transform: Some models remove bias in FFN layers to improve training efficiency and reduce redundant parameters (Ex : LlaMa).
-
Training vs Fine-tuning:
- Pretraining: Optimized for whole sentence/document prediction.
- Fine-tuning: Optimized for suffix generation—only the generated completion is used for loss calculation, not the given input.
-
Alignment: Ensures the model adheres to human preferences and ethical considerations.
- LLMs initially generate unaligned responses, sometimes toxic or unsafe.
- Alignment achieved via SFT + RLHF post pretraining (used in ChatGPT, Claude, LLaMA-2 chat variants).
-
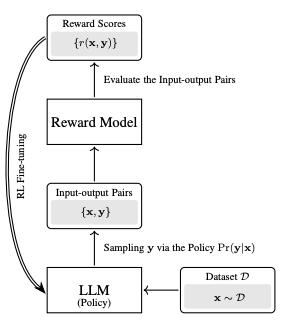
Reinforcement Learning from Human Feedback (RLHF):
- RL uses an agent with a policy to interact with an environment and receive feedback via a reward model.
- In LLMs:
- Agent: The LLM.
- Policy: Prefix completion mechanism.
- Reward Model: A learned function scoring responses based on human preference.
- RLHF Steps:
- Generate multiple completions.
- Collect human rankings.
- Train the reward model using ranking loss.
- Optimize the LLM’s generation policy based on the reward model.
- [CLS] Token Use:
- Encoder models (e.g., BERT) use
[CLS]to represent input. - Decoder-only models (e.g., GPT-4, LLaMA-2) append a special token at the end instead, as attention is causal.
- Encoder models (e.g., BERT) use
RLHF Summary
-
Training at Scale:
- High-Quality Data: Up to 90% of web-scraped data is filtered out (used in GPT-4, LLaMA-2, Claude).
- Diverse Data: Inclusion of programming/math improves reasoning (seen in GPT-4, CodeLLaMA).
- Bias Mitigation: Balance gender, age, and cultural representations.
- Privacy Considerations: Anonymization of sensitive information.
-
Distributed Training:
- Data-Parallelism: Each worker handles a fraction of the batch size (used in LLaMA-2, GPT-4 training).
- Model-Parallelism: If a model is too large, different layers are placed on separate GPUs (used in GPT-3, GPT-4 due to massive parameter sizes).
- Tensor-Parallelism: Splits matrix multiplications across GPUs (used in LLaMA-2, GPT-4 for efficient inference).
- Pipeline-Parallelism: Uses staggered batch processing to avoid idle GPUs.
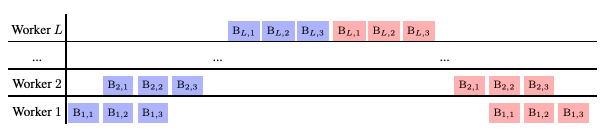
Pipeline Parallelism
- Mixed-Precision Training:
- Uses lower precision (fp16/fp8) for forward/backward passes but full precision for weight updates.
- Reduces memory and computational cost but requires careful handling of floating point non-associativity.
-
LLM Scaling Law:
- Describes how increasing model parameters and dataset size improves performance.
- Generally follows a power-law with irreducible error as a plateau.
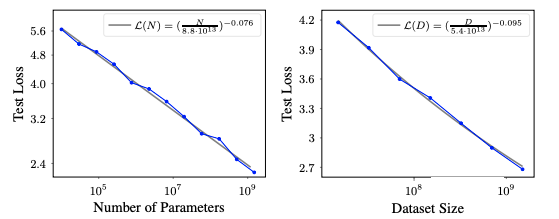
Scaling law in LLMs